
狂雨CMS如何制作采集规则
前言
狂雨小说内容管理系统(以下简称KYXSCMS)提供一个轻量级小说网站解决方案,基于ThinkPHP5.1+MySQL的技术开发。KYXSCMS,灵活,方便,人性化设计简单易用是最大的特色,是快速架设小说类网站首选,只需5分钟即可建立一个海量小说的行业网站,批量采集目标网站数据或使用数据联盟,即可自动采集获取大量数据。内置标签模版,即使不懂代码的前端开发者也可以快速建立一个漂亮的小说网站。狂雨小说cms 1.5.3 - 狂雨小说cms - Powered by HYBBS (kyxscms.com)
帮助文档:采集规则 · 狂雨小说cms · 看云 (kancloud.cn)
安装好狂雨cms不会采集数据等于白搭,而一条采集规则30-50不等,所以不如自己学会如何采集,这样既能省money又可以学知识。
教程开始
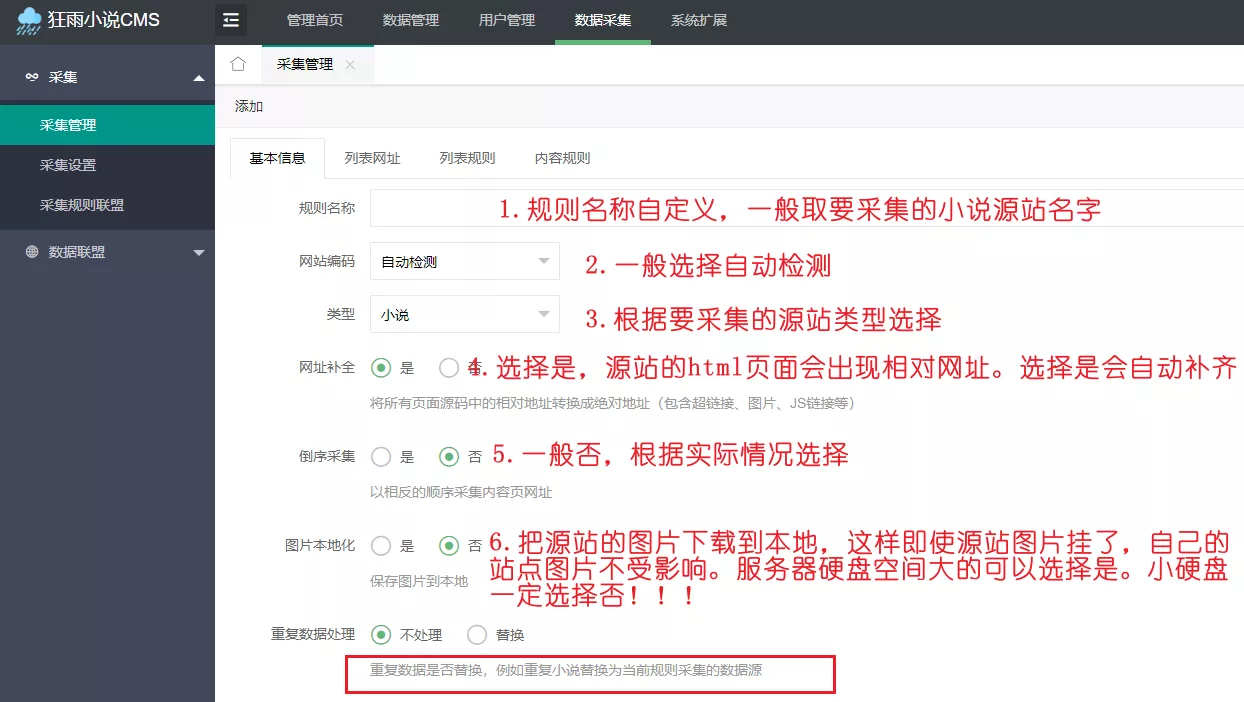
填写采集规则的基本信息
- 名称规则自定义,一般以要采集的源站名命名。
- 网站编码默认自定义即可。
- 采集小说站,类型选择小说
- 采集顺序,一般否即可
- 图片是否本地化,根据自己服务器硬盘大小选择。有的源站一张封面图40kb左右,甚至更大,那么采集十万本小说,图片可能占用四五个g,或者更多。
- 重复数据是否处理要看是否多次采集,如果一个站点之前有使用其它采集规则有了数据,那么再使用新的采集规则很有可能会采集到与之前重复的数据,所以这时候需要判断是否把重复的数据替换成当前采集规则采集的数据。
添加小说列表页,或者叫采集小说列表页url
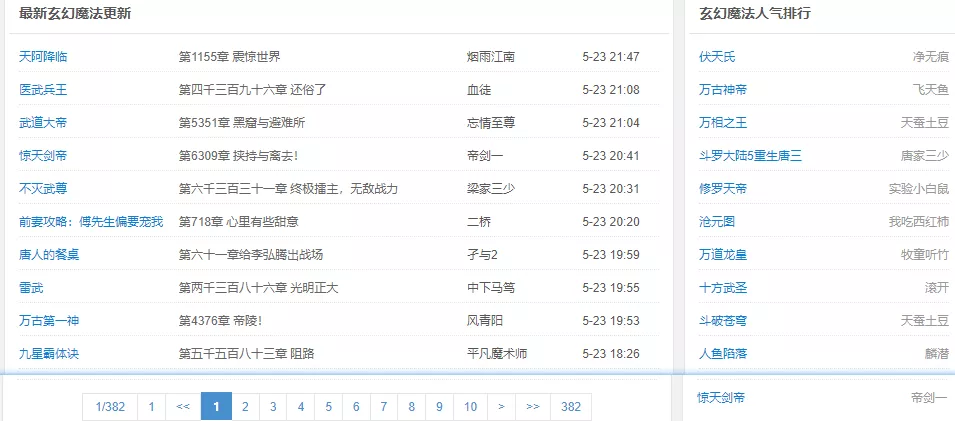
经常看小说的朋友会很熟悉下面的页面。打开在线小说站,点击玄幻分类的页面就是大致如此。想查看更多玄幻小说就会切换到第二页,第n页面。下图玄幻的总共382页,切换的时候会发现地址栏的页面地址url的后几位数字是着随切换页面有规律的同步增加。当然也有部分小说站隐藏了下方供读者切换的页面的按钮,但是其实点击小说多去观察,其实还是这个规律,在地址栏手动输入数字同样可以进入小说列表页。如果没有以上的小说列表页规律是无法使用狂雨cms整站自动采集的。比如有的站点是真正意义上没有小说列表页,地址栏的url只在进入具体一部小说时才会看出规律时就不适合整站采集,只能采集默认显示的那个首页页面。
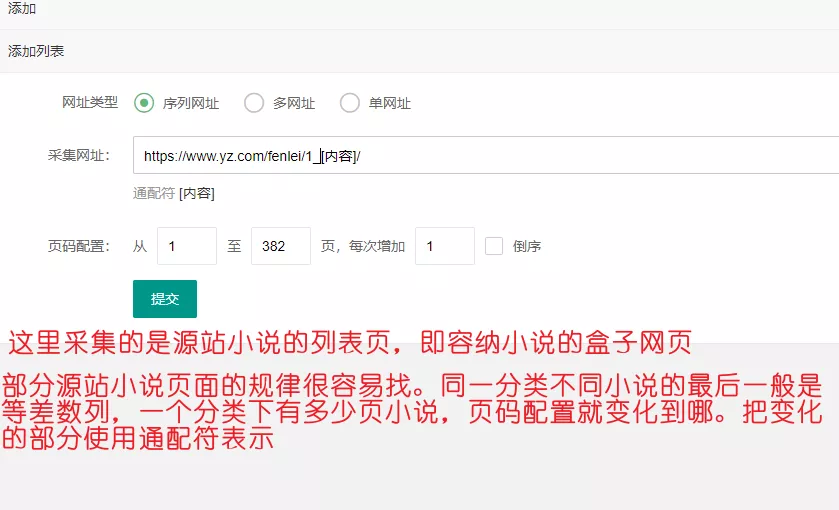
列表页的采集网址填写小说列表页的网址,即出现类似上图的小说列表页(小说盒子)时,浏览器地址栏的网址。有几个分类就添加几条,分类的规律页面数字需要手动根据地址栏切换分类时的变化规律改动。每个分类有多少页面就在页码配置处填入相同的最大页面数字。这个步骤会实现循环遍历目标采集站点的所有小说列表页。这个过程类似你手动挨个切换页面查找想看小说的动作。填写好后点击提交。可以先提交一个分类网址,等后面测试采集规则没有问题再回来全部添加。而看小说,没人只会一直停留在选择小说的页面,看到想看的小说就点击进去,进入某部小说的详情页。
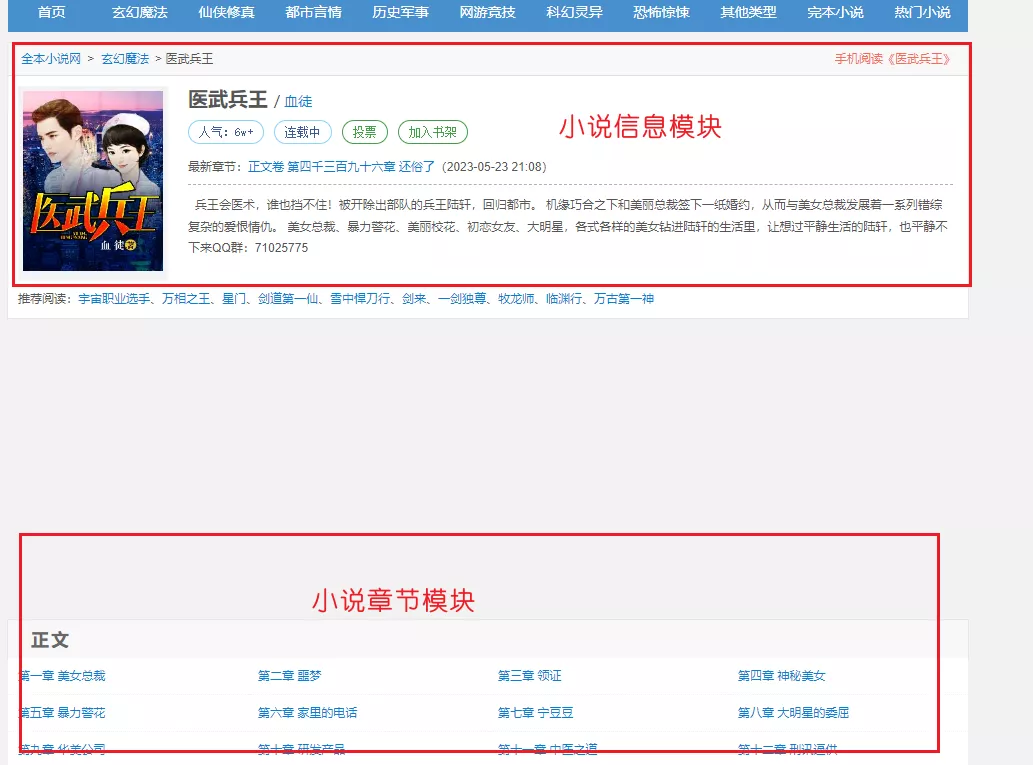
采集小说内容页面,即获取每本小说的url
上面把所有小说的列表页(小说盒子)的url的获取到了,这个过程其实就是你在来回切换页面查找想看的小说的过程。而当你被某一部小说的名字吸引想要更进一步了解这部小说的时候,就会点击这部小说,进入这部小说的内容页面。如下图的小说内容页面,能够看到这部小说的一些信息,比如名字,连载情况,简介,封面,章节等信息。那么要如何获取每部小说的url呢。
每部小说的url其实就在你点击进入的小说列表页面,在小说列表页面点按ctrl+u或者右键查看网页源代码,就能看到小说列表页的html源码。在这里面就包含了这个页面所有小说的ulr地址。
获取小说url的区间
查看网页源代码后,首先要找到能够包住所有小说的起始位置和结束位置。
如下图的起始位置最新玄幻更新,最后一部小说的名字是修复师。
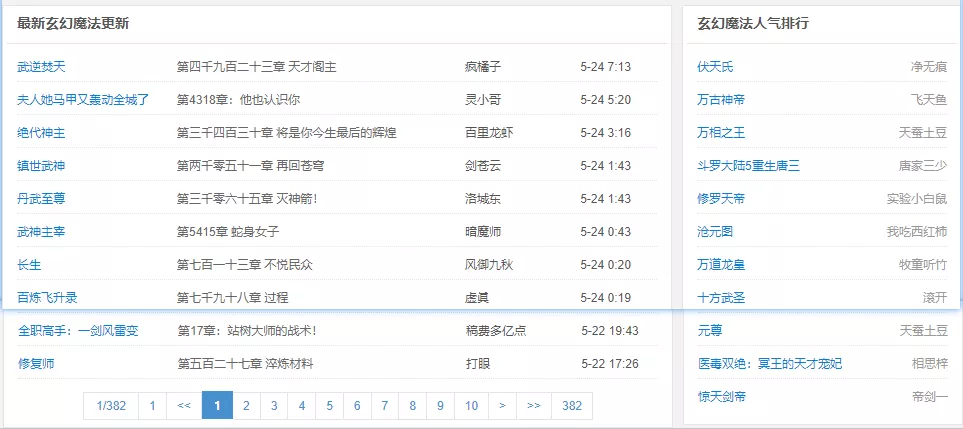
查看源代码获取起始位置。在源码页面按ctrl+f搜索最新玄幻魔法更新就可以定位到下图。在这个位置的前后继续使用ctrl+f来查找这个页面的唯一代码串,<div id="tlist">和<ul class="titlelist">都是这个页面的唯一代码串。

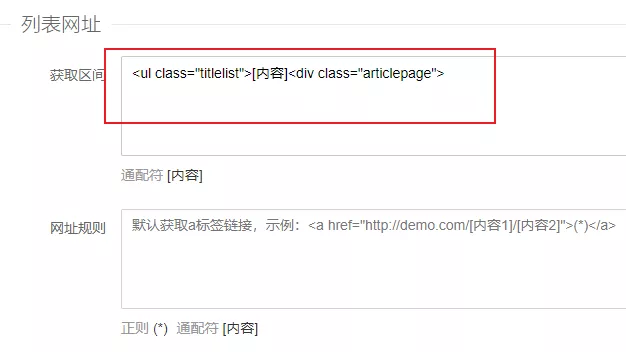
在列表网址的获取区间框填入如下,下图的起始位置选择的<ul class="titlelist">。结束位置同理要选择唯一的代码串。原则是起始位置的代码串要在第一部小说之前,结束位置的代码串在最后一部小说的后面。把要获取的区间使用通配符[内容]代替。这样就能进准获取到该页面所有小说url所在的位置。
填写网址规则
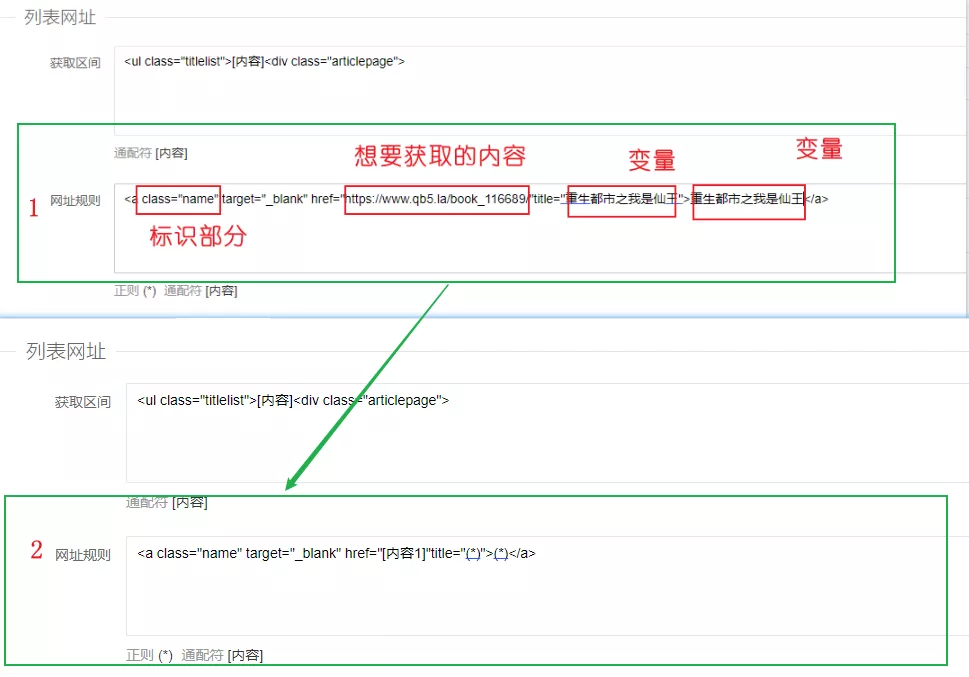
在这个区间有许多其它代码标签,并非想要的小说url,所以需要再添加一条网址规则,去精准提取url。
如下任意复制一部小说的a标签(<a >开始,</a>结束)。把想要获取的内容替换成通配符[内容](选中想要替换的内容,点击下方的通配符[内容]按钮即可),把变量替换成正则(*)。因为要采集所所有小说的url而不是这一部小说的url,所以要设置成变量,正则(*)可以代表任何字符。
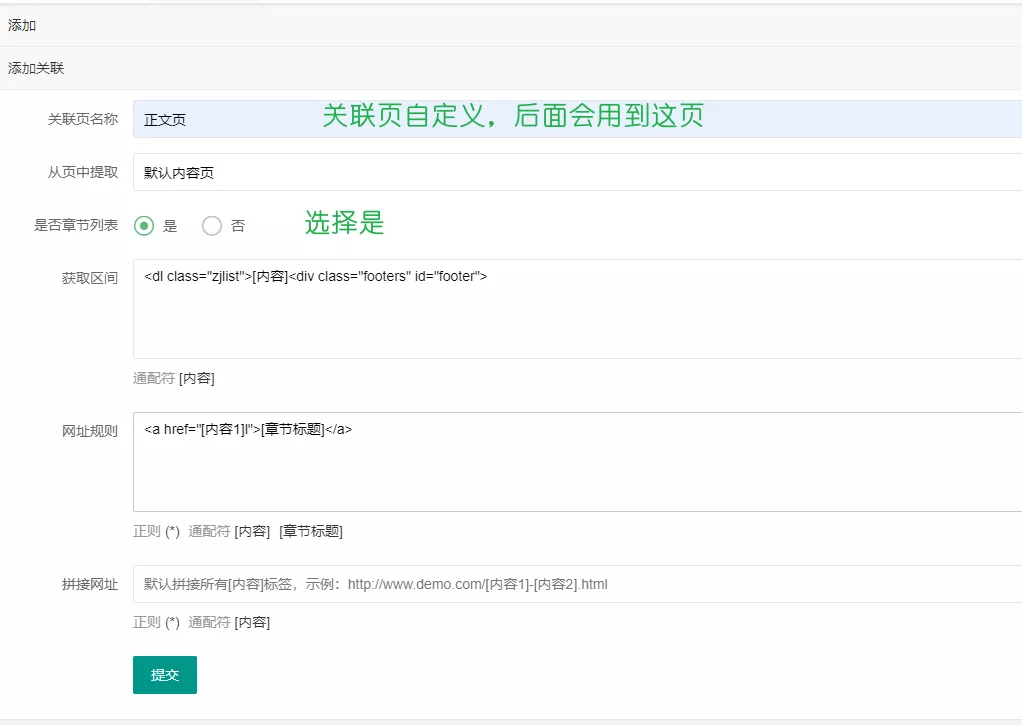
采集小说的正文页面(关联页)
获取章节url区间
上面完成了所有小说url的提取,即可以查看所有小说的内容页。而看小说并非只是看一个小说的内容页,看到某部小说还不错,就会点击章节正式开始看这部小说的正文。所以下一步要提取小说的章节url,章节url在小说的内容页。
在上面的页面,按住键盘的ctrl+u,或者右键查看网页源代码。要找到章节页唯一的起始位置和结束位置。以上面的为例,可以看到第一章的前面是正文二字,因此在进入源码界面后按ctrl+f弹出搜索框,在搜索框输粘贴正文然后回车,初步定位章节内容页的起始位置。在章这个位置的上下位置,找到这个源码页唯一的代码串,方法还是按ctrl+f,下方的<div class="zjbox>"或者<dl class="zjlist"都是唯一值,可以作为起始位置。
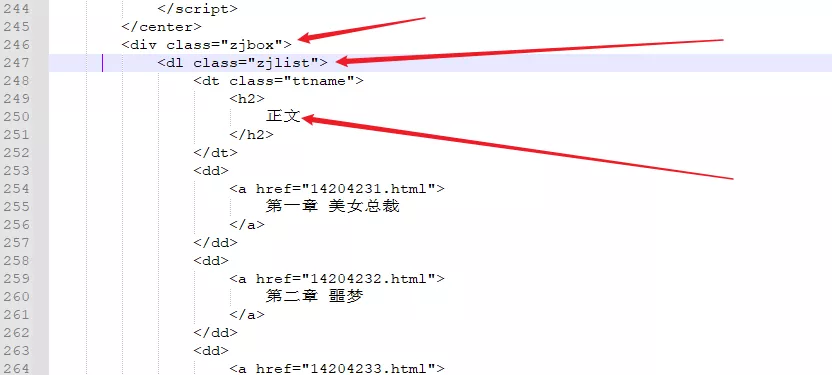
注意:原则是要把所有章节都包在里面,而且在起始位置和结束位置中间的包括的代码尽量不要有除了章节url的其它url地址。

起始位置和结束位置找到后,就可以如下填写列表规则的获取区间。
填写网址规则
虽然通过起始位置和结束位置可以把所有的章节url"包在里面",但是可以看到这里面有很多杂七杂八的其它代码标签,并非url地址。所以接下来填写要采集的网址规则来采集章节url。
填好后点击提交
内容规则
这部分提取的内容会作为你小说站点的小说信息,比如小说所属分类,小说作者,小说的名字,小说的封面图,连载情况,还有最重要的小说正文内容,和章节名称信息。除了小说的正文内容和章节名称,其它的都需要在目标的站点的小说内容页面获取,小说内容页面(详情页)看小说内容页面图。小说的正文和章节名称需要在正文页面获取。
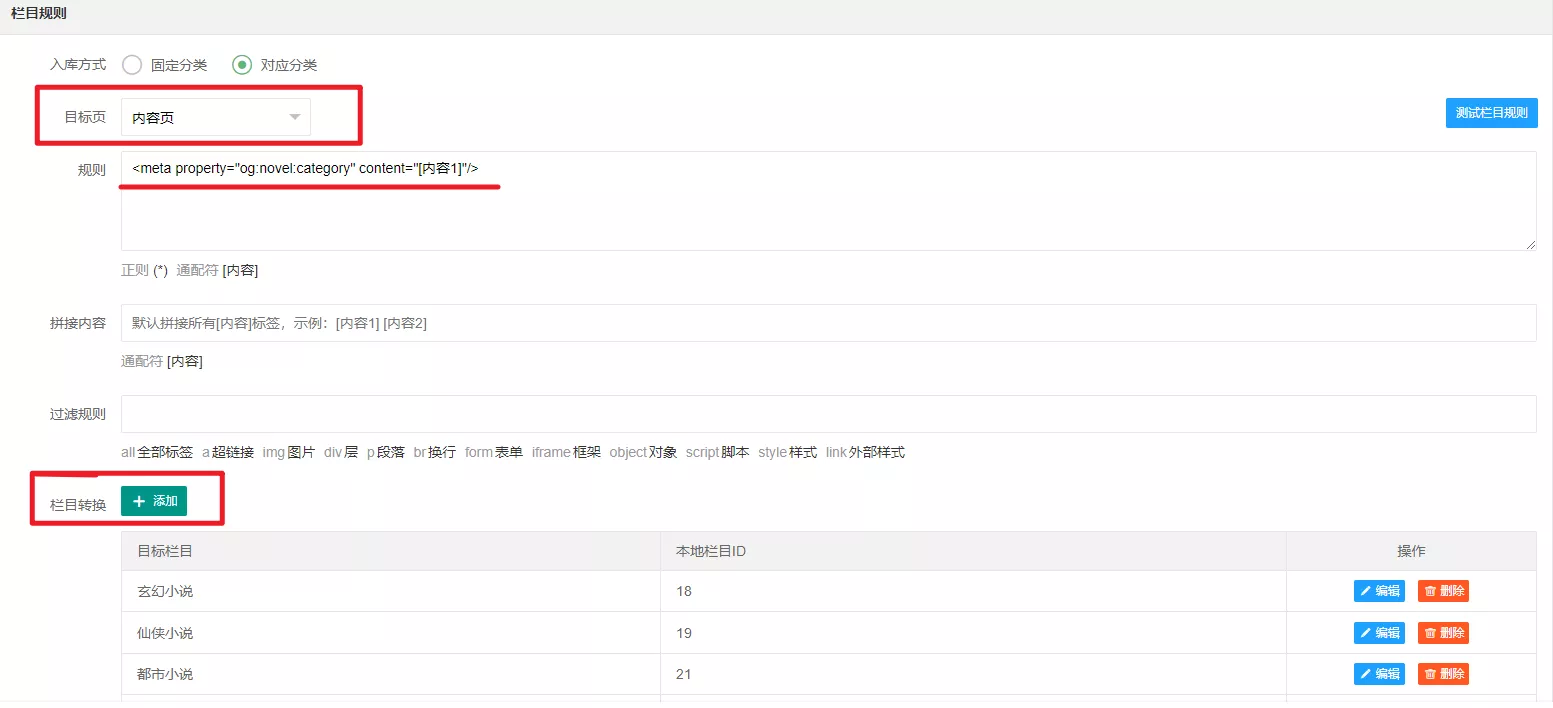
栏目规则
栏目规则是要获取一篇小说的所属分类,比如它是属于都市还是玄幻亦或者其它分类。
- 栏目规则的目标页面选择
内容页(不要选错) - 规则需要结合内容页面的源码来填写,使用
ctrl+u,ctrl+f。提示:在任意一部小说的内容页查看源码,搜索这部小说的所属分类,会出现多个符合的结果,选择一个前后有唯一标识的代码串,一般选择在head标签内的meta标签。如果head标签没有,再去选择其它适合的。 - 同样把想要获取的内容(小说的所属分类)替换成
通配符[内容] - 根据源站的分类,添加栏目转换
- 填好后,点击测试栏目规则,测试结果没有出错,出现符合的内容就说明规则是对的
一般head标签内的规则是这么写的:(切记不要照搬!!!)
1 | <meta property="og:novel:category" content="[内容1]"/> |
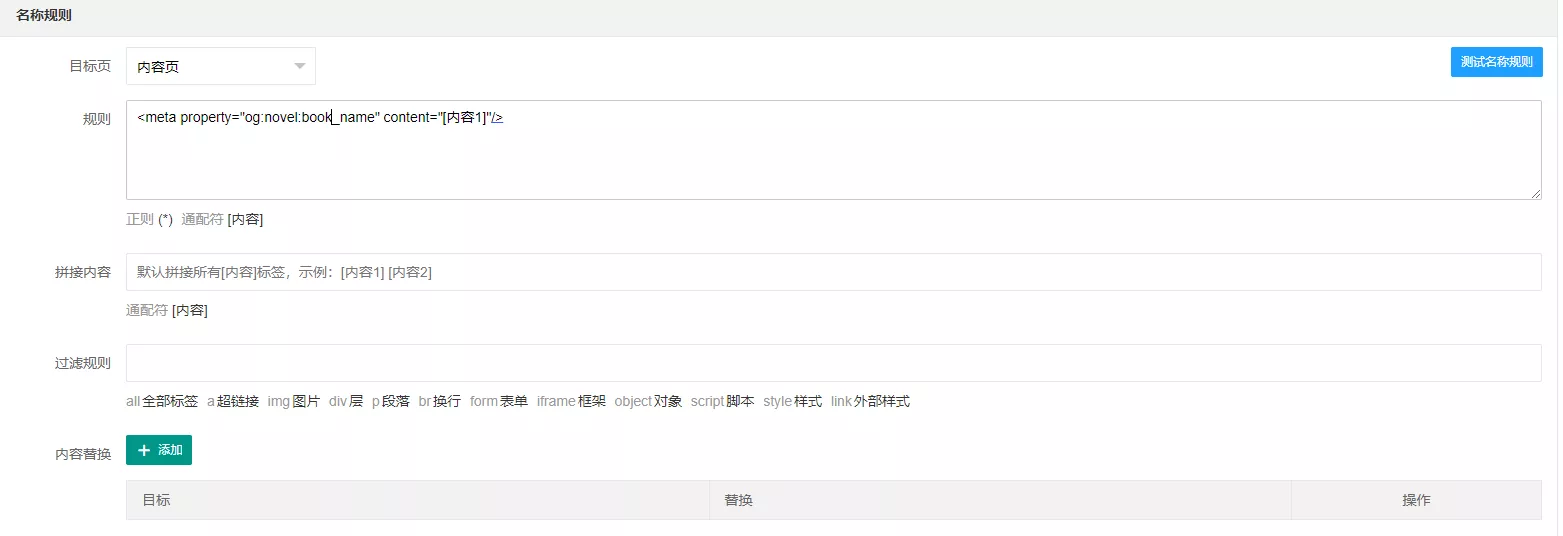
名称规则
同栏目规则
一般head标签内的规则是这么写的:(切记不要照搬!!!)
1 | <meta property="og:novel:book_name" content="[内容1]"/> |
作者规则
同栏目规则
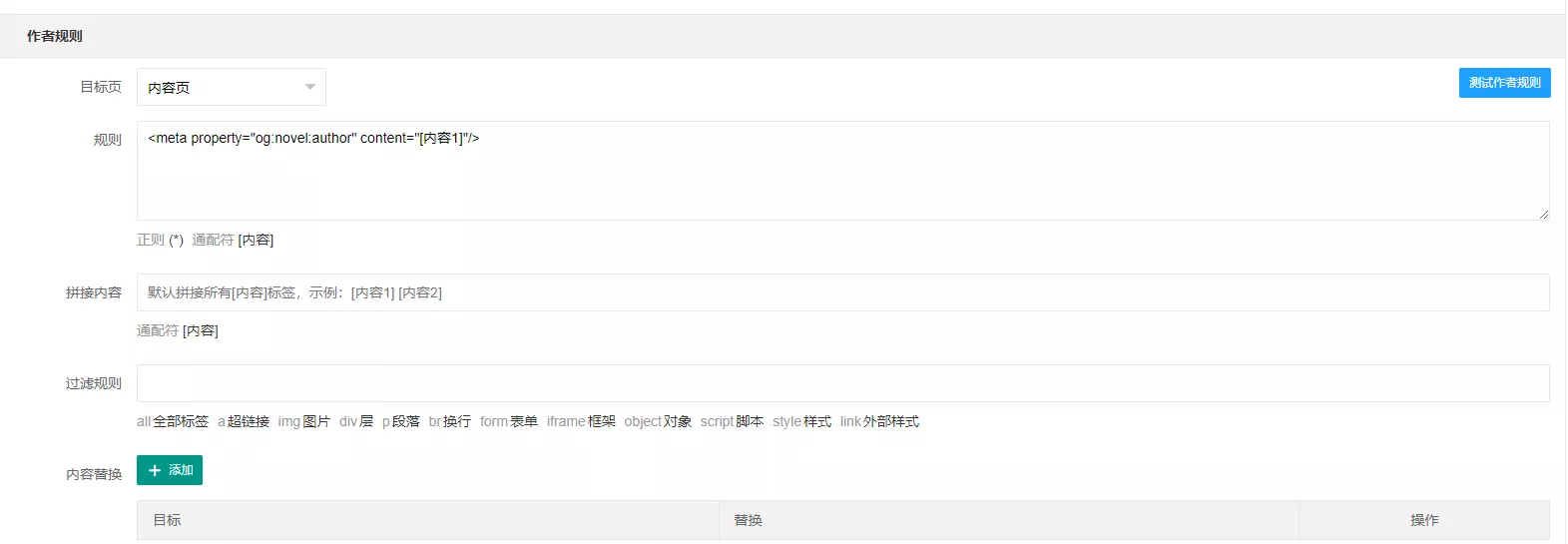
一般head标签内的规则是这么写的:(切记不要照搬!!!)
1 | <meta property="og:novel:author" content="[内容1]"/> |
连载规则
同栏目规则
有些小说站点在head标签可能没有小说的状态,这时候也可以使用最近更新,或者最后更新等关键词来获取时间信息。
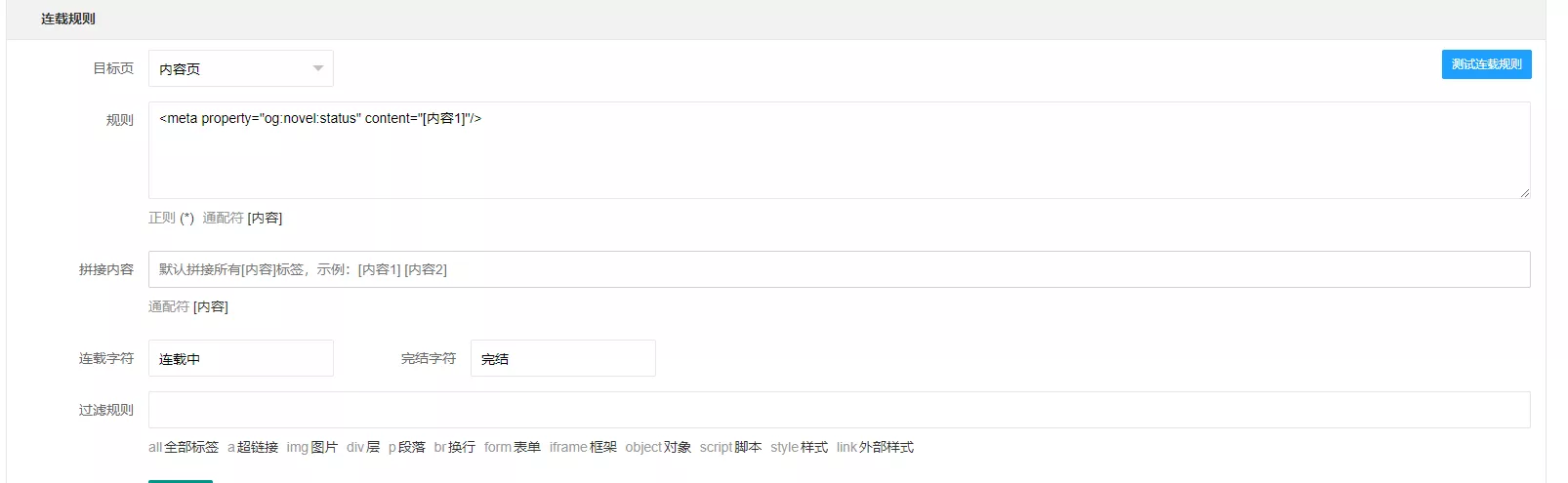
部分有head标签内的规则是这么写的:(切记不要照搬!!!)
1 | <meta property="og:novel:status" content="[内容1]"/> |
图片规则
同栏目规则
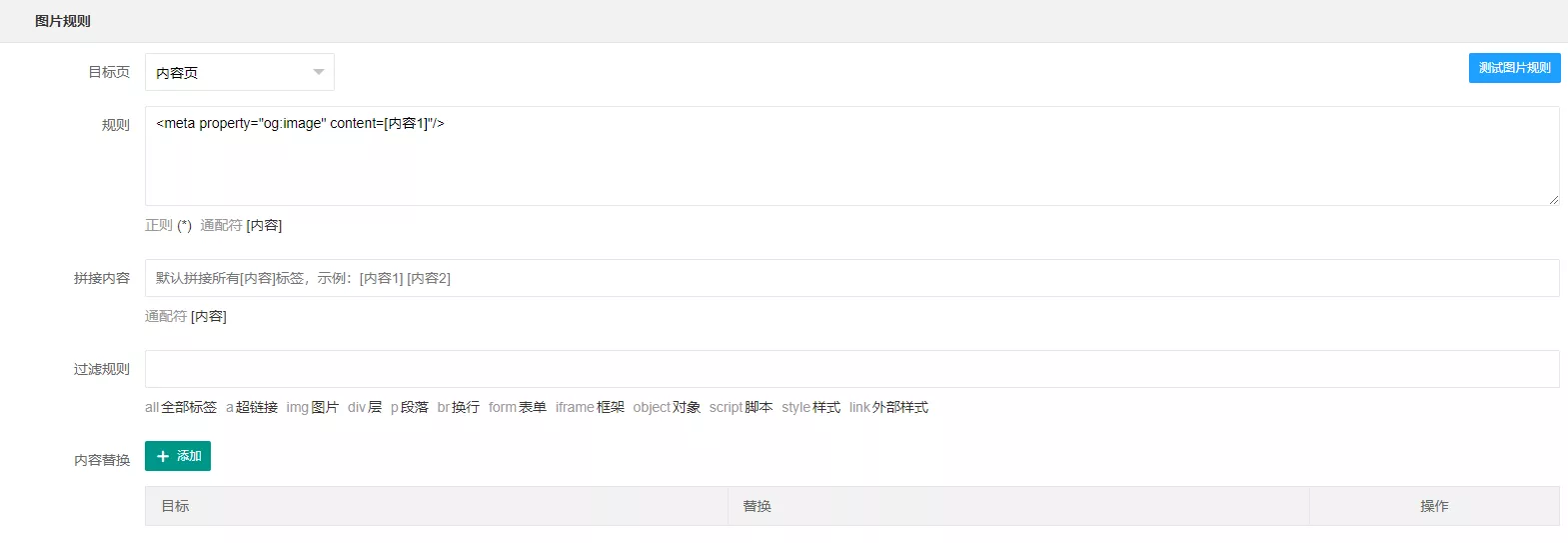
一般head标签内的规则是这么写的:(切记不要照搬!!!)
1 | <meta property="og:image" content=[内容1]"/> |
标签规则
小说的标签似乎也没看到是啥
所以标签规则个人目前用的还是是栏目规则,直接把栏目规则复制过来。
章节名称规则
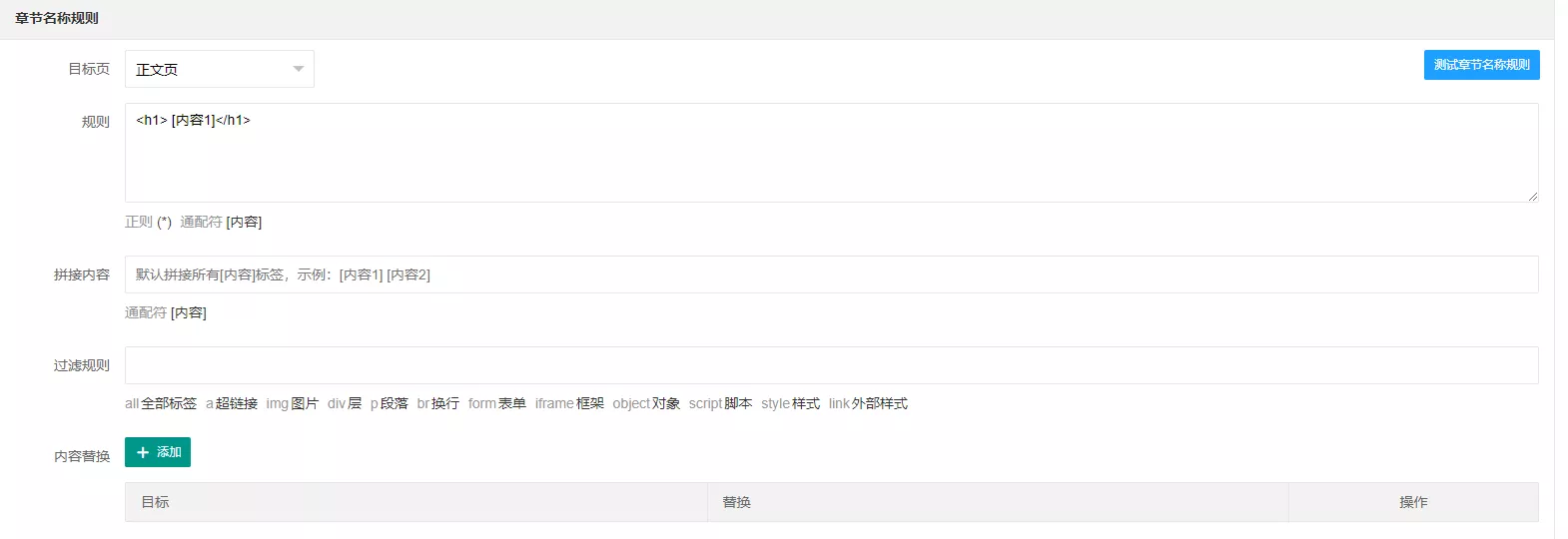
目标页一定使用自己之前创建的关联页,个人之前创建的关联页名称是正文页,所以选择正文页。在正文页查看网页源代码,章节的名称一般就是下面的。
1 | <h1> [内容1]</h1> |
章节内容规则
目标页一定使用自己之前创建的关联页,个人之前创建的关联页名称是正文页,所以选择正文页。在正文页即正式看小说的页面查看网页源代码,找出能够“包住”想要获取的章节内容的。
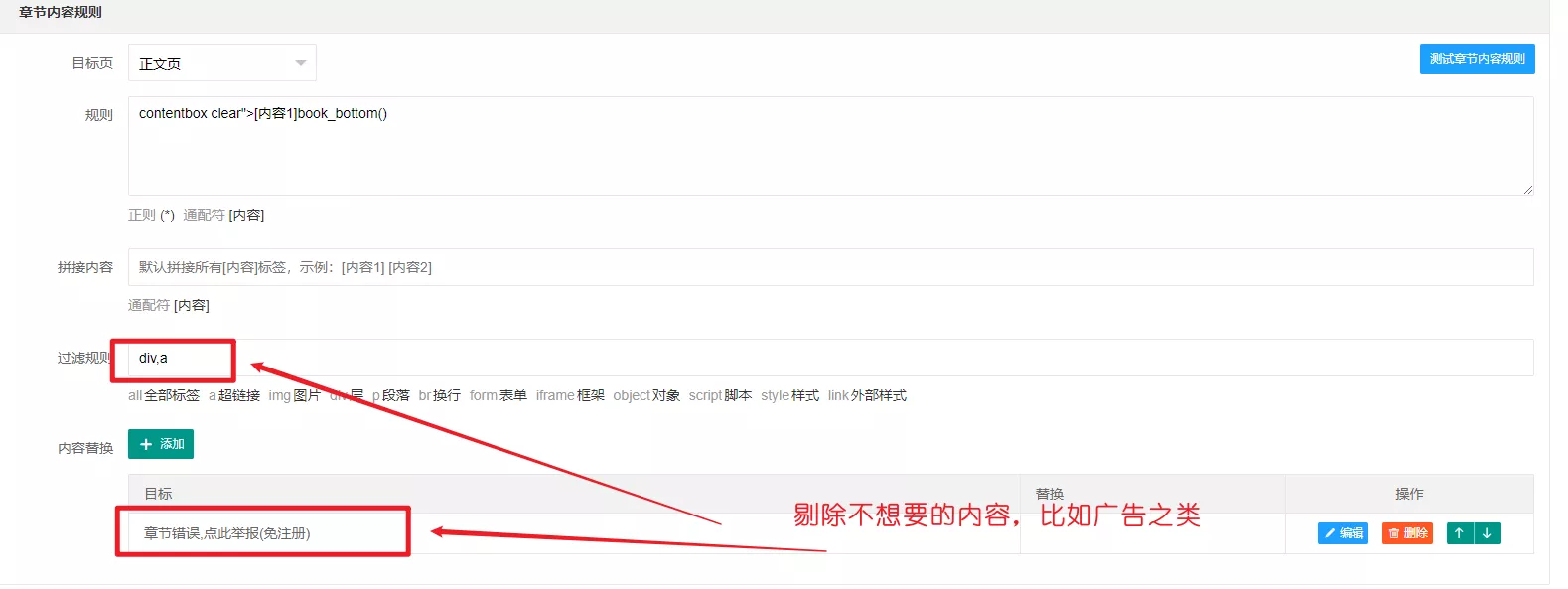
补一个正文页示例

总结
- 学会查看网页源代码(ctrl+u),并且使用ctrl+f去定位所需内容的位置
- 查找唯一的开头和结尾代码标识,把想要的内容
包住 - 理解正则的替换,灵活使用正则替换
了解一丢丢html的知识以及正则表达式的概念会更快的学会如何采集。或者反复尝试几次编写自然就会了。




